Mount Data to a Job
In this guide, we will explain how to attach one or more datasets to a job. First, let's review some basics about FloydHub datasets.
Datasets¶
A Floyd dataset is a directory (folder) of data that can be used during a job. To create a new dataset, please follow this guide. You can view the datasets you have created in the datasets page in the dashboard. You can also view public datasets by searching for them on FloydHub.
Why keep data separate from code?¶
A data scientist tweaks his/her code often during the process of creating a deep-learning model. However, he/she doesn't change the underlying data nearly as often, if at all.
Each time you run a job on FloydHub, a copy of your code is uploaded to FloydHub and run on one of FloyHub's powerful deep-learning servers. Because your data isn't changing from job to job, it wouldn't make sense to keep your data with your code and upload it with each job. Instead, we upload a dataset once, and attach, or "mount", it to each job. This saves a significant amount of time on each job.
Beyond that, keeping data separate from code allows you to collaborate more easily with others. A dataset can be used by any user who has access to it, so teams and communities can work on solving problems together using the same underlying data.
Mounting a Dataset¶
What does it mean to "mount" a dataset to a job?¶
In the world of file systems, the term "mount" means to attach one file system or folder to another file system. For example, when you insert a flash drive (which is a mini file system) into your computer, its file system gets mounted to your computer's main file system so that you can retrieve, remove, or save data to the flash drive. Once the flash drive is mounted to your computer's file system, other programs can access it as if it were a native part of your computer's file system. This same mounting pattern is how datasets are handled on FloydHub.
When you use the floyd run command to run a job, your code will be sent up to
FloydHub and run on a powerful deep-learning server that can run your job. If
you want your code to be able to access a dataset during the job, you need to
mount the dataset to the server where the job is running (just like you need to
plug a flash drive into your computer in order to access its files). Mounting
datasets to a job is easy: just pass the --data flag to the floyd run cli
command as detailed below.
The --data flag¶
To properly use the --data flag with floyd run, you need to specify two
things:
- The name of the dataset you want to mount. (Note: this command can take shortened dataset and output names)
- A name for the folder where the data will be accessible to your code during the job, we call this the "mount point". You can give this folder (mount point) any name you want.
These two things are separated by a : with no spaces. Here's the syntax:
floyd run --data <data_set_name>:<mount_point> …(rest of run command)
Let's go through a couple of examples to show how to mount one or more datasets to your job.
Example 1¶
The command below will mount FloydHub's public
Udacity GAN
dataset at /my_data
floyd run --data floydhub/datasets/udacity-gan/1:/my_data "python my_script.py"
A couple of things to note:
- There is no space between the name of the dataset
(
floydhub/datasets/udacity-gan/1) and the mount point name (/my_data). - A colon (
:) is used to separate the name of the dataset and the mount point. - Datasets are always mounted at the root directory (
/). This means that if you specify/fooas the mountpoint, your data will be mounted at/foo. If you specifyfooas the mount point, your data will still be mounted at/foo. Preceding the mount point with a/is optional‒your data will be mounted at the same location either way. You'll see us use both variations in this guide. - Nested mount points are not supported. This means mount points like
my_data/fooor/home/me/datawill not work. If you need your data available at a nested directory, check out the Symlinking mounted data guide.
Important
A common mistake is to for code to reference a mounted dataset without a
preceding /. If you specify my_data as the mount point for your
dataset, your code needs to look in /my_data to find the dataset. Without
the preceding /, your code will look for the dataset in the wrong place
(the directory the code is running in). In your code, always precede your
references to the mount point with a /.
Example 2¶
This example spins up a Jupyter Notebook and mounts the
VGG 19-layers
dataset under /vgg:
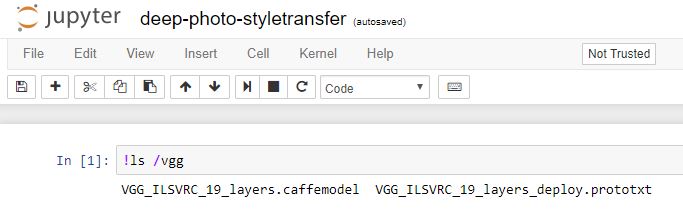
floyd run --data floydhub/datasets/vgg-ilsvrc-19-layers/1:vgg --mode jupyter
/vgg.
Mounting the output of another job¶
You can link jobs by mounting the output of one job as the input of a new job. This allows you to iterate on the ouput of a past job.
You can refer to the output of a job by its name with /output appended to it.
For example: mckay/projects/quick-start/1/output refers to
the output of the job mckay/projects/quick-start/1
Use the --data flag in the floyd run command, mount past output to a job,
just as you would to mount a dataset. For example:
$ floyd run \ --data mckay/projects/quick-start/1/output:/model 'python eval.py'
This will make the output of mckay/projects/quick-start/1
available at /model for the new job to use.
Note: You need to have access to a job to be able to mount its output.
Mounting multiple datasources¶
You can attach up to five datasources (datasets and/or job outputs) to a job
using the --data flag in the floyd run command. Ensure that each mount
point is unique.
$ floyd run \ --data udacity/datasets/mnist/1:digits \ --data udacity/datasets/celeba/1:celeb \ "python script.py"
In this case, the above datasets will be mounted at /digits and /celeb,
respectively.
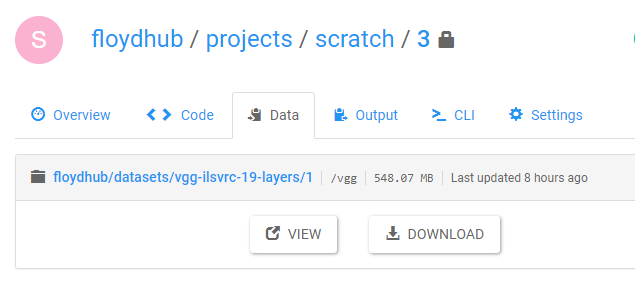
Viewing mounted datasets in the web dashboard¶
You can view the mounted datasets and their respective mount points for a specific job by going to the Data tab:
Symlinking your mounted data¶
Floydhub's basic data-mounting functionality is sufficient for most users' needs. However, if you find yourself with more complex requirements, symlinking can almost certainly provide a solution.
Here are some common FloydHub data-mounting needs that symlinking can solve:
- Code requires the data to be available at a location that is not valid with
the mounting syntax of
floyd run --data. - Multiple mounted datasources need to be available under a single directory.
- Directories in a single datasource need to be split into their own locations.
For documentation on symlinking, please see this guide: Symlinking mounted data
Understanding dataset names¶
The full name of a datasource (<username>/datasets/<dataset_name>/<version>)
consists of three parts:
- Username
- Dataset Name
- Version
For example: udacity/datasets/mnist/1
Default mount points¶
We highly recommend that you explicitly specify the mount points for your data
using the --data <data_name>:<mount_point> convention.
If, however, you do not specify a mount point, the default values are:
-
Single data mount: If you only mount one datasource without specifying a mount point, it is mounted at
/input -
Multiple data mounts: If you mount multiple datasource without specifying mount points, they will each be mounted under their respective GUIDs (e.g.
/xKduBzTr4LAsc6eVPZVPVd). GUIDs are 32-character random strings that difficult to track down, so we highly discourage this pattern.
Help make this document better¶
This guide, as well as the rest of our docs, are open-source and available on GitHub. We welcome your contributions.
- Suggest an edit to this page (by clicking the edit icon at the top next to the title).
- Open an issue about this page to report a problem.